利亞德集團再次成為業界焦點,以雷霆之勢一口氣收購了三家相關領域的公司,進一步拓展其在計算機及通訊設備租賃市場的版圖。這一舉措不僅展現了利亞德雄厚的資本實力,也預示著公司在智能化設備服務領域的戰略升級。
此次收購的三家公司分別專注于計算機設備租賃、通訊設備租賃及相關技術服務,與利亞德現有業務形成高度互補。通過整合資源,利亞德將能夠為客戶提供更全面的一站式設備租賃解決方案,覆蓋從硬件到軟件、從日常辦公到大型活動的多樣化需求。在數字化轉型加速的背景下,企業對高效、靈活的IT設備依賴日益加深,利亞德的此次布局無疑抓住了市場機遇。
行業分析人士指出,利亞德此次收購是其多元化發展戰略的重要一步。公司已從傳統顯示技術領域逐步向智能設備租賃、物聯網服務等新興業務延伸,旨在構建更完整的產業鏈生態。收購完成后,利亞德有望通過技術協同和渠道共享,提升整體運營效率,增強市場競爭力。
此舉還可能推動計算機及通訊設備租賃行業的整合浪潮。隨著5G、人工智能等技術的普及,設備租賃市場正迎來快速增長期,但競爭也日趨激烈。利亞德通過資本運作快速擴張,或將在行業內引發連鎖反應,促使更多企業尋求合作或并購以鞏固自身地位。
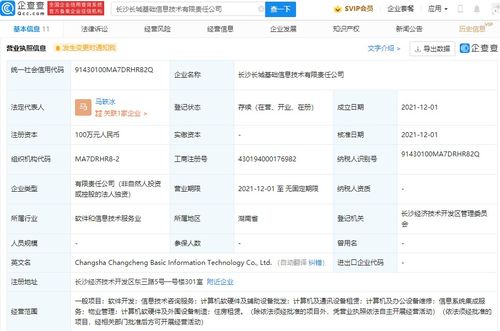
盡管收購細節尚未完全披露,但市場對利亞德的這一動作普遍持樂觀態度。投資者認為,這有助于公司降低業務單一性風險,開拓新的盈利增長點。利亞德是否會將收購范圍進一步擴大至上下游關聯產業,值得持續關注。
利亞德的“又雙叒叕壕”之舉不僅是一次商業擴張,更是其對未來科技服務趨勢的敏銳洞察。在設備即服務(DaaS)模式興起的今天,這一次收購或將成為利亞德邁向更廣闊舞臺的關鍵跳板。